‘Ole lot of llama going on: First time using Ollama with Llama3
Llama 3 came out last week and I was keen to spin it up. This also felt a good time to try Ollama as it had been cropping up in my feeds and had some nice features. Principally amongst these was that the model ran separately from any scripts or notebooks and could be called via a locally running API. This means you can have multiple scripts running simultaneously that can all access the same model — very useful in development. You can also query the model from the command line — to get help on a function or format some text — a great help!
Ollama is like Docker for LLM models — in that you can define the model you want via a file definition, like a Dockerfile, which will then be instantiated.
Maybe you want to change the prompt type, maybe change the context length — and as long as you’ve specified where to obtain the base model from, which can be a local file or the name of a popular model and it will be created for you.
Behind the scenes Ollama is using llama.cpp to run the models meaning they can be run on CPU only machines. Any fast processor and enough RAM can run one. A GPU if you have one will also be used for speedup — subject to correct drivers being installed.
I installed Ollama under Windows Subsytem for Linux (WSL) using the instructions from their website which performs the install and sets up Ollama to run as a service.
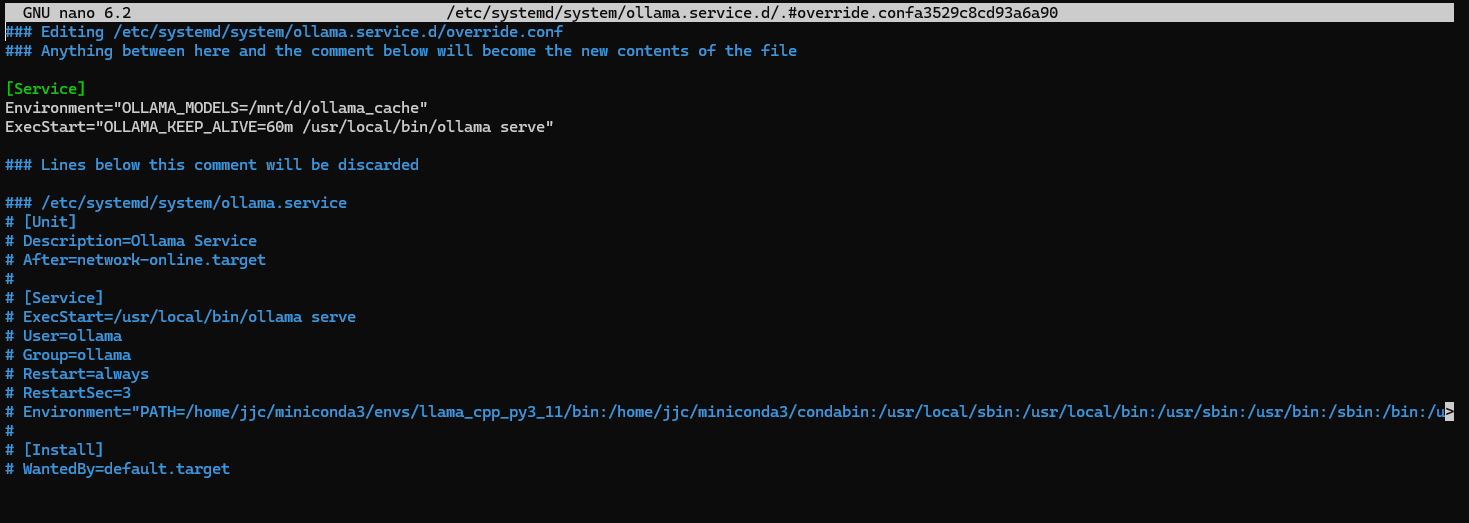
curl -fsSL https://ollama.com/install.sh | shBefore running a model I wanted to define the storage location for the files. These are large, at least ~3GB, and I wanted to store them on a separate data partition. It took a bit of looking but to change the default storage location meant altering the service parameters for Ollama. I did this with systemctl which alters the service config files:
systemctl edit ollama.service
This was a little scary as the config file that pops up tells you various parameters are going to be discarded but they are only going to be superseded by what you add here.
Then make sure to restart the service with these commands:
systemctl daemon-reload
systemctl restart ollamaThen you can type:
ollama run llama3Which will download the llama3 model, in this case the 8B version which is a 4.7GB file, and start a command line chat. This will take some time.

To communicate via the API instead, package up your the request up as JSON and use curl to send the command directly to the interface.
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "Why are so many models called llama?",
"stream": false
}'Use stream : false to request that the model return the response as a single entry otherwise it will return each word as they are generated which is a little harder to follow.
There is also a python package (that acts as an API wrapper) and interfaces for Langchain and LlamaIndex.
I had some initial problems with the model file I’d downloaded via Ollama — this being a cutting edge there seemed to be a problem with some End of String (EOS) tokens causing the model to keep looping and talking to itself (and amusingly agreeing with itself!) however this had been corrected in another model file [link] and I could download that.
I was able to both see the original issue and confirm it had been corrected by examining the logs generated and see the model being loaded. Viewing service logs can be done using the journalctl tool.
To view the last 100 entries use:
journalctl -u ollama -n 100 --no-pagerOr to set up a continuous display logging use:
journalctl -u ollama -fTo fix the my model issue I created a new Modelfile using the prompt settings for Llama3 but point to the new GGUF file.
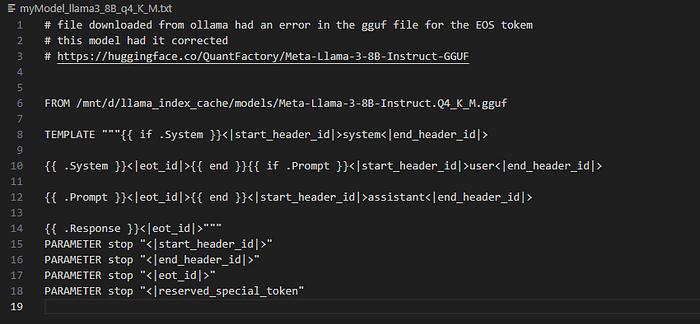
I could then create and label this new combination by running:
ollama create myModel -f myModel_llama4_8B_q4_K_M.txtAnd subsequently load the new model using its associated label:
ollama run myModelOne initial annoyance I found was Ollama letting models time out of memory. By default this timeout is 5 mins but given each LLM can take a good few minutes to load it was annoying if it was subsequently unloaded automatically.
Two methods I used to address this were:
Another change to the service file using systemctl to set the default keep_alive time to 60 mins. (don’t forget to reload and restart!)
Adding a keep alive flag to the API calls
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"stream": false,
"keep_alive": -1}'You can also set keep_alive to 0 to unload immediately.
In conclusion, Ollama is a great way to access and operate LLM models that gives plenty of access methods, easy customisation and a good selection of popular models ready to download.

This story is published under Generative AI Publication.
Connect with us on Substack, LinkedIn, and Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!


